Face Mixer Diffusion
I'm still trying to catch up on writing up some of the "old" diffusion experiments I did and models I made during 2022. This is another quick write up of a model designed to generate new images of a person's face given a single image of that face with no further fine tuning. There are now better models available for this purpose, in particular take a look at IPAdapter face and PhotoMaker.

Feed forward Dreambooth? #
Shortly after Stable Diffusion was released Dreambooth showed how to fine tune such models for particular styles subjects or people, I've known for a while how much people are obsessed with their own faces, and for a while Dreambooth led to a blossoming of short lived apps and websites for generating images with your own face in (who knows maybe they still exist, people seem to endlessly love their own face).
Dreambooth is somewhat cumbersome as a technique in that it involves multiple example images and training the diffusion model itself. I had fully been expecting someone to come up with a model which could do the same task but without the need for subject specific training, but it seems like that's been a somewhat challenging problem, the first hints of models which can do this (although still not with the level of likeness that Dreambooth could achieve) are only just coming out now.
Of course I had a go myself. The aim being to make a model which you could give a single image of a face and for it to make new images of that person. I took an approach that skipped out the text prompt all together, fine-tuning Stable Diffusion to take an image of a person, crop out the face region, and used a pretrained model to make tha into a vector to use as the condition for generating a new image.
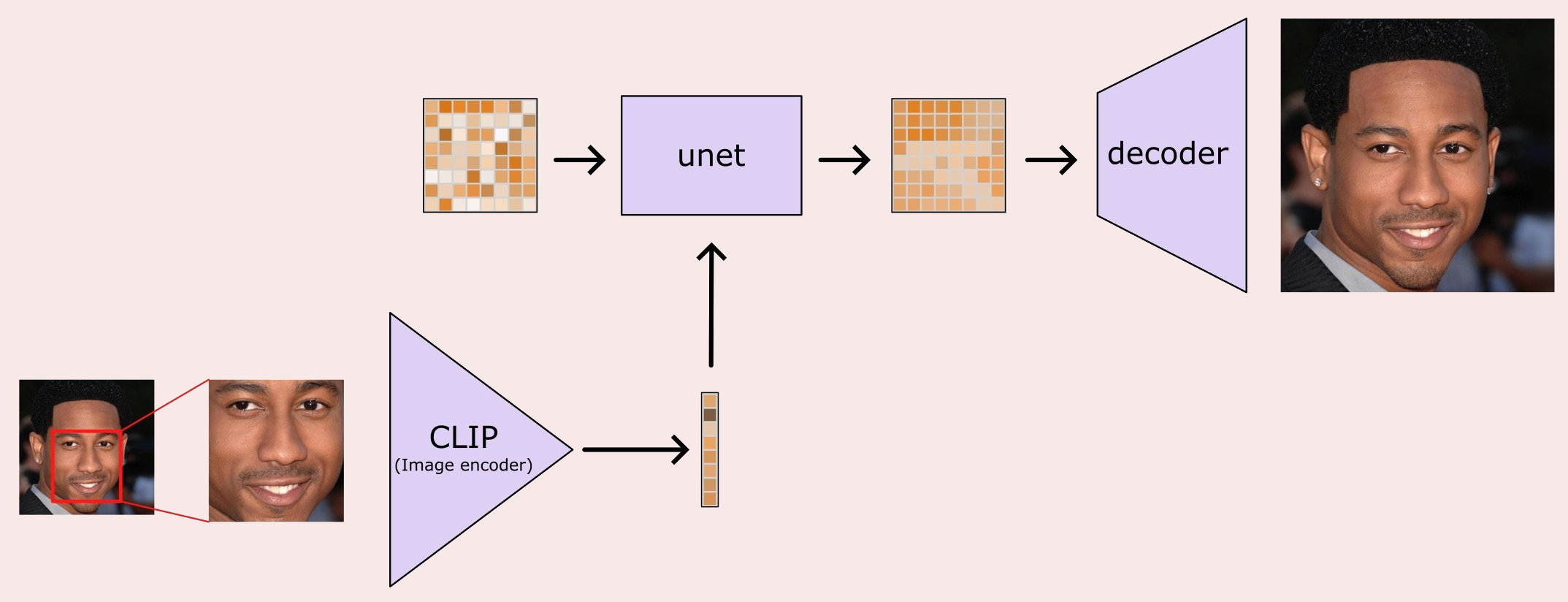
I tried a few variations of the concept, not all of which I can remember honestly, but all were trained on datatsets of aligned faces, where I could easily extract a central crop which contained only the face and the rest of the image contained all the "other stuff" (hair, background, accessories, hats, etc.). For all the models I took the central crop and then ran it through an image encoder, either CLIP or a pretrained face recognition network, both would give a vector representation of the face. This can then be passed to the cross attention layers instead of the text embeddings as in the original model. After training like this for a while you can pass a new image of a face, crop and extract the appropriate embedding then use this to generate a new image of (hopefully) the same face.
Results - Making faces #
My first model was trained on FFHQ using an open source face recognition network as the face ID embedding. After training the samples looked promising when I took random faces from FFHQ and asked the network to create new images of the same person.

Unfortunately, when I tested in on validation images (faces that the network hadn't seen during training), things weren't so good. The model generated a set of consistant faces of people, but not of the input image. I guess this network had overfit on the original training dataset, FFHQ only has around 70k images, which is tiny by modern standards, I had tried to apply some image augmenation to the faces before passing them to the face recognition network but it seems like this wasn't enough. It gets some features right, there is a clear focus of the ID network on shapes of noses, but these samples don't really resemble the original people at all.

Back to CLIP #
As an alterative face encoding I went back to trusty old CLIP image embeddings which are clearly very well proved out when it comes to conditioning a diffusion model. I followed the same procedure as above, but used the LAION CLIP-L model to extract the embedding vector correspdonding to the face region. (I might also have resumed from my existing image variations model, but I can't remember).


Trailer Faces HQ and retrieval training #
Around the same time I made a large dataset along the lines of FFHQ, but with data scraped from movie trailers called Trailer Faces HQ (TFHQ) (I'll blog about that sometime too). As well as being a lot bigger than FFHQ, it also had a lot of repeated faces, both from different shots of the same trailer, as well as the same actor in different movies. This meant that if I could find the corresponding sets of images I could train my model with retrieval, in other words instead of just taking a crop of the face and trying to augment it with some image transforms, I could use a different image of the same person.

Controlling face and background #
Making new images of a person is nice, but at this point I've stripped out all the text control, so the face embedding is the only way to control this model 1. I wish I'd done some more experiments like embedding interpolation, SDEdit type image-to-image, or multi-cfg on the different embeddings, but I didn't at the time, and now I've lost the checkpoint! .
To try and add back some control I trained a new version with an extra embedding added corresponding to the background of the image (i.e. all the image with the face region masked out in grey). Apart from that everything is the same, and once trained if you give a single image, and extract a face and background embedding, then you can again generate new images of people's faces:
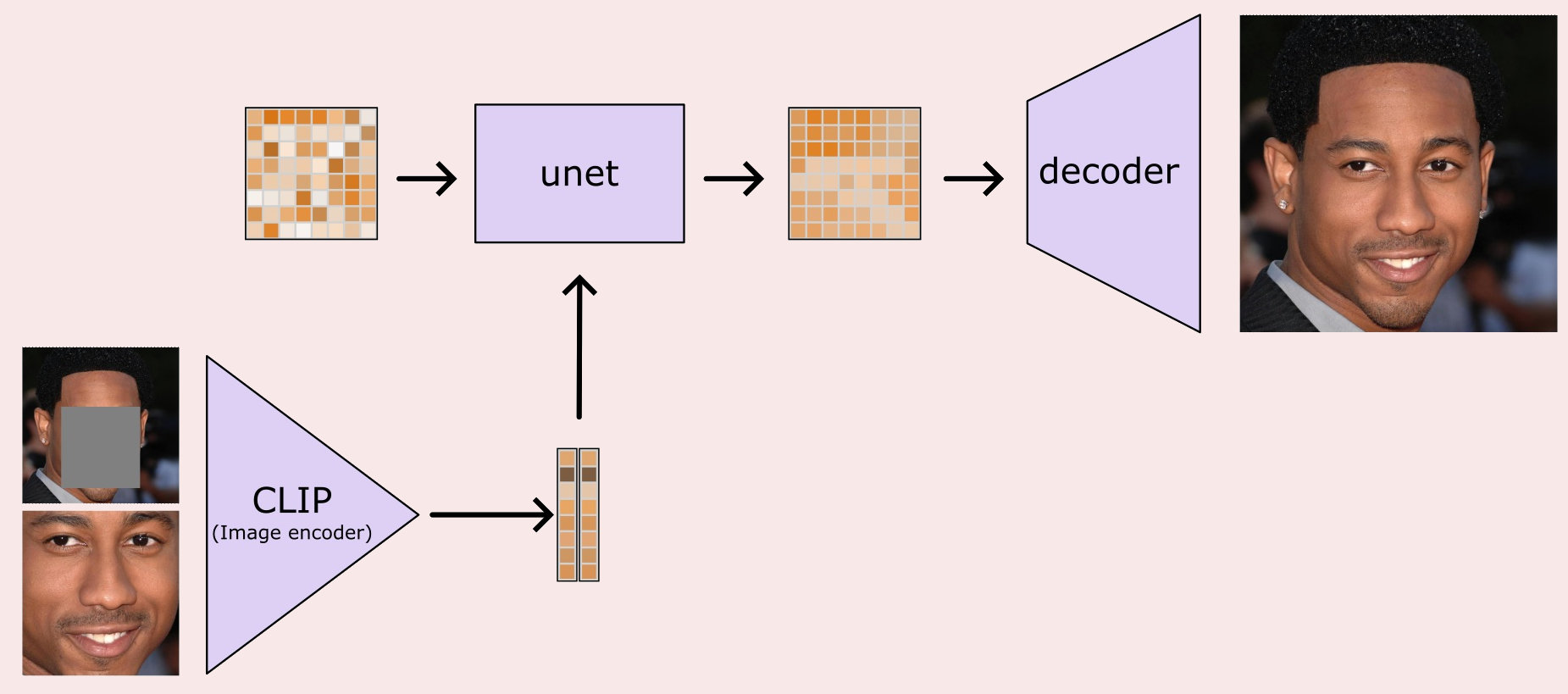

It gets more interesting when you mix the face embedding from one image, with the background embedding from another. In an ideal world you should get an image of the person in image 1, with the hair/lighting/hat/background etc, of image 2.

And it sort of worked! Many of the generated images do appear to be the original person, and you do pick up various features from the the "background" image. Some things change that you might not expect like gender, and other things stay fixed like expression, which is reasonable given the simple way I divided up the image for the different embeddings.
Where did I put that checkpoint again? #
This was all quite a long time ago, back at the end of 2022, but I've only just got round to writing about it all. I was going to share the models too, but unfortunately I seem to have misplaced them, I really have no idea where the saved checkpoints are now, I have a so many hard drives and folders of checkpoints, but none of them seem to be the right ones. Oh well.
If you really want to you could train the things yourselves. All the config files are in my Github repo, and CelebA, FFHQ, and TFHQ are all things you can download.
I also talked a bit about this model, along with a bunch of others, in the Hugging face diffusers talk.
I liked the old StyleGAN Face mixing vibe I got with this model:
Some related work #
After I tweeted about this blog post a couple of people pointed out some similar work. Bolei Zhou mentioned the great IDinvert from back in the good old days when GANs ruled the image generation roost, and Yong-Hyun Park pointed me the way of this recent interesting paper on content injection using the "h-space" of Unet based diffusion models.


- Previous: Würstchen v2 Pokémon
- Next: Image Mixer Diffusion