Image Mixer Diffusion
Just want to play with the model? Try it on Lambda labs or Huggingface
I'm doing more catching up with write ups of past models I trained, this time it's the turn of "Image Mixer" at the time I did at least share the checkpoint and a demo, but here's a more detailed write up of the process of training the model itself.
Even before I worked there I was very impressed with Midjourney's blend feature, where you can combine two (or more) images together 1. I'd love to see someone make a version of Infinite Craft but blending images instead of words. . This way of prompting always resonated with me as it gave me vibes of interpolating in StyleGAN's latent space.
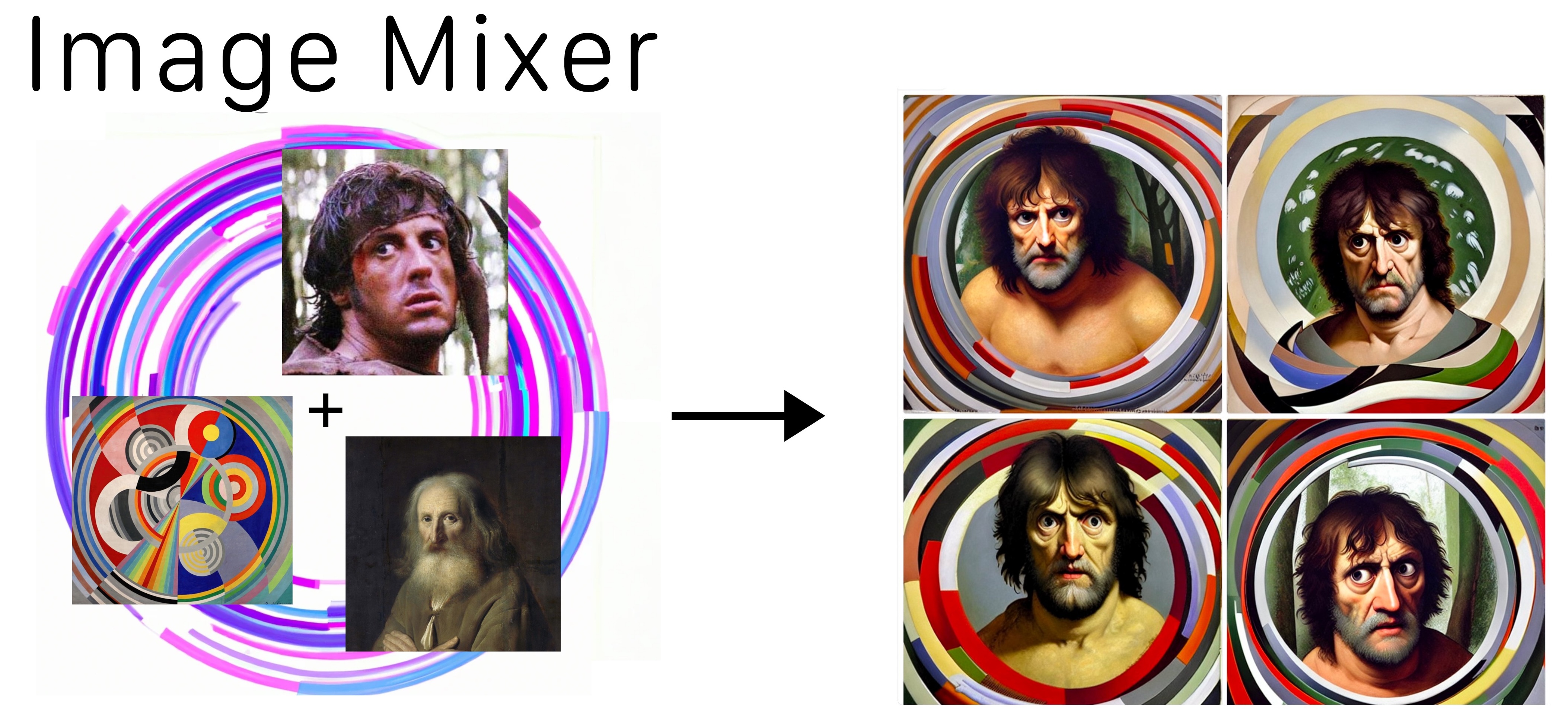
In this type of image blending everything gets mixed together in a big soup roughly 50/50, so the style content and objects in the image all end up mixed together between the two images 2. Now we have more fine-grained ways of blending images in Midjourney, Style and Character references let you take specific aspects of source images and they are great! . This gives very cool effects but I wanted to explore a more "compositional" method for image blending, i.e. taking the elements from each image and placing them together in a new image. The resulting model was Image Mixer, I don't think it really succeeded, but that's what I was going for, and something fun came out anyway.

To make the model I fine tuned my image variations model, instead of using the clip embed of the whole image to condition the diffusion model, I took several small crops of a single image and used all those image embeds as conditions (concatenating them into a sequence of tokens). The hope being that the model will learn that it has to use the appearance and objects visible in those crops, but will figure out how to compose them together into a reasonable image.

Sometimes it works a bit, but it doesn't quite get there in general. I increased the training resolution to 640x640 to give me space to extract crops which didn't contain too much of the original image. The model does manage to mash different concepts together although the image quality can be somewhat off sometimes, and it still tends to blend the concepts together. The other nice effect is that you can add text conditions as the model is trained to use the shared image text latent space of clip 3. Of course you can do most of these things using the base Image Variations model too, and mix images either by averaging or concatenating embeddings .

I also tried training a version which had one global clip embed of the full image and a set of smaller crops. I was hoping that would allow a more style transfer sort of approach with the global embed controlling the content and the local ones more able to affect the details of texture and style. It didn't work out that way unfortunately.
Still it's a fun model to play with, even if it's a bit outdated by modern image generation standards. Take it for a spin, here or here, or download the checkpoint.
Some more examples:







- Previous: Face Mixer Diffusion
- Next: Experiments with Swapping Autoencoder