Stable Diffusion Image Variations

This post is time-travelling a little. For some reason I never blogged about the image variations stable diffusion model I trained, so this is a bit of a recap on the how and why of the image variation model and to collect some links and experiments using it. The model itself is a little old now and there are other models which are similar might be better like Karlo v1.0 and Kandinsky (probably not the Stable Unclip though
0. For some reason the Stable Unclip is actually terrible quality. This is an example of the output when using my typical Ghibli house image for testing (hint it's really bad) 
As soon as the original stable diffusion was released I wanted to see how I could tweak the model beyond regular fine tuning. The image variations shown in the original dalle2 paper were always really compelling and this model presented the first chance to actually reproduce those (without lots of training resources). The key part would be to somehow pass images encoded as clip embeddings to the model rather than text embeddings.
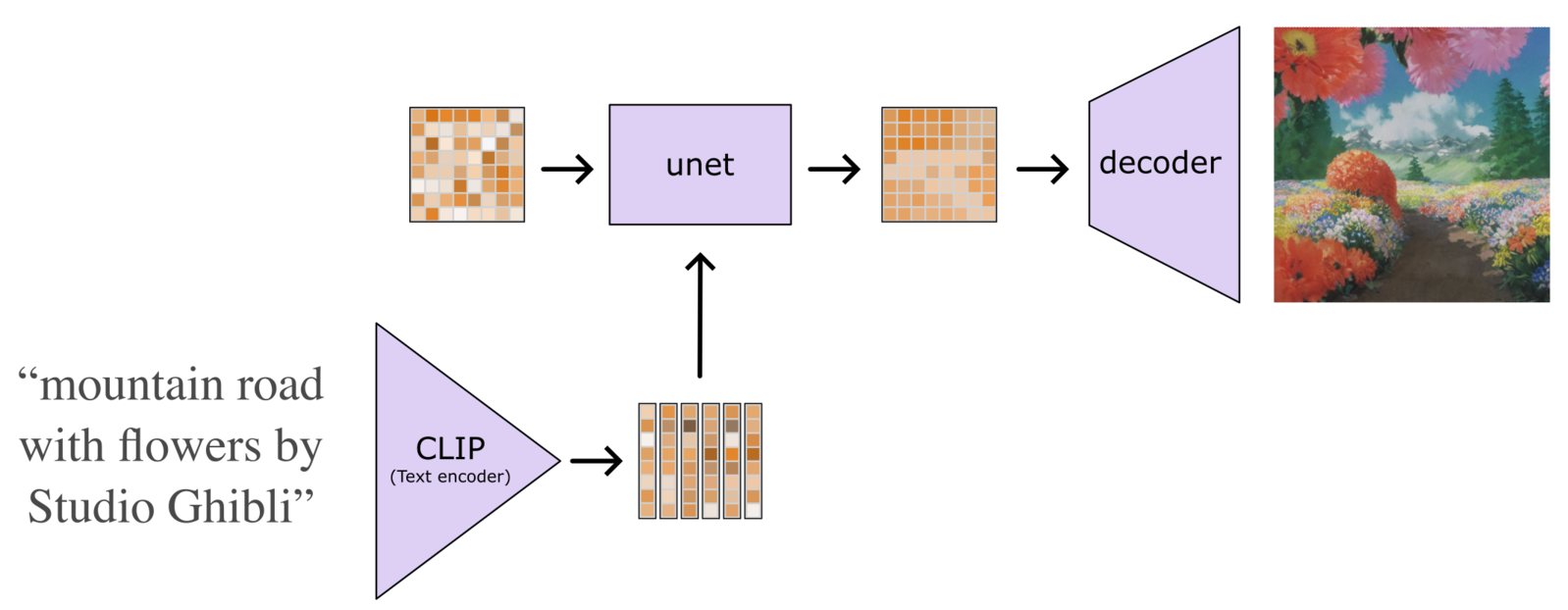
Originally I mis-understood the architecture of stable diffusion and assumed that it took the final clip shared latent space text embedding and thought I might just be able to swap this out for an image embedding, but actually stable diffusion takes the full sequence of pooler and token embeddings, so I couldn't simply swap them out 1. I did do some experiments trying to generate these word embeddings from image embeddings but they never panned out .
So instead I decided to swap out the conditioning altogether and fine tune the model to accept projected image embeddings from clip. So instead of using the text encoder to make a set of (batch_size,77,768) dimension CLIP word embeddings, I used the image encoder (plus final projection) to produce a (batch_size,1,768) size image embedding. Because this is just a shorter sequence it's easy to plumb into the existing cross-attention layers.
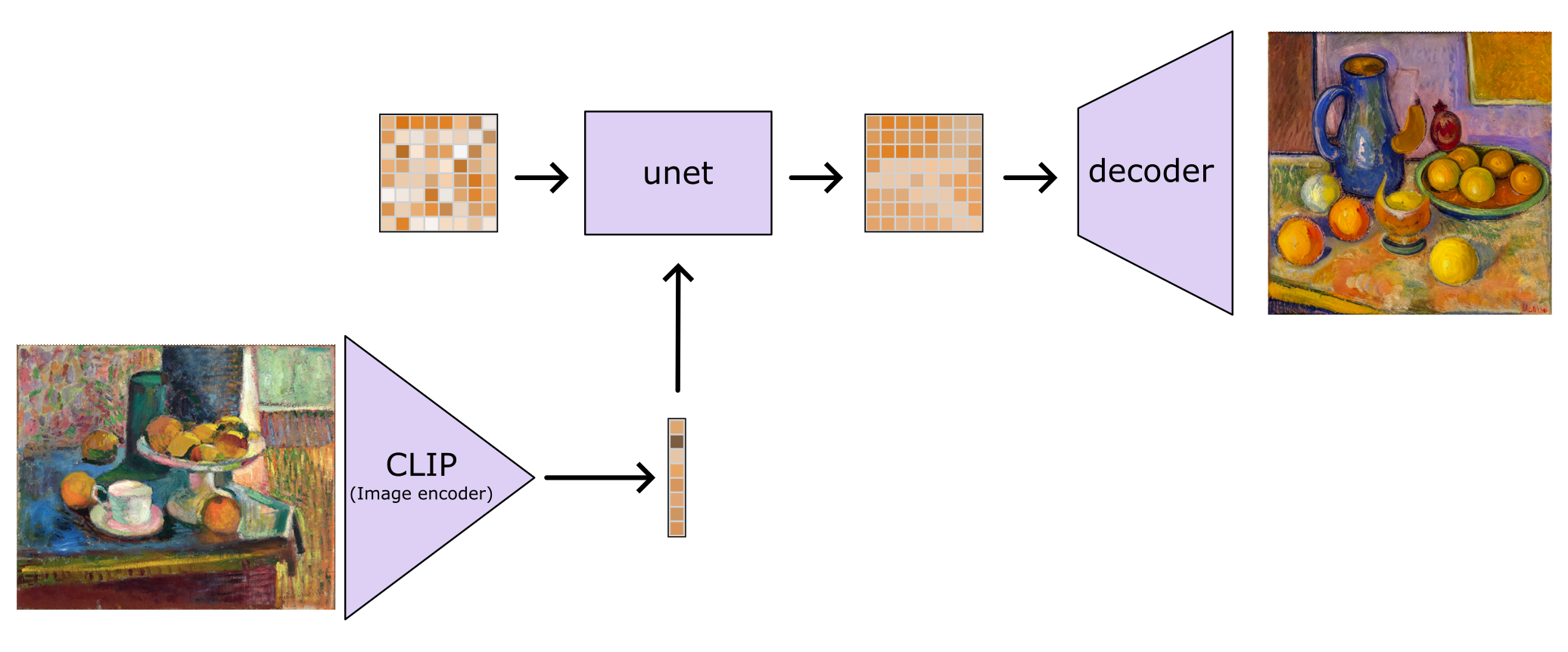
With some simple tweaking of the original training repo I could finetune the model to accept the new conditioning, there are more details on the training in the model card, but here's a quick summary 2. This is actually the training procedure of the v2 model which was trained for longer and more carefully, giving better results :
- Fine-tuned from the Stable Diffusion v1-4 checkpoint
- Trained on LAION improved aesthetics 6plus.
- Trained on 8 x A100-40GB GPUs
- Stage 1 - Fine tune only CrossAttention layer weights
- Steps: 46,000
- Batch: batch size=4, GPUs=8, Gradient Accumulations=4. Total batch size=128
- Learning rate: warmup to 1e-5 for 10,000 steps and then kept constant, AdamW optimiser
- Stage 2 - Fine tune the whole Unet
- Steps: 50,000
- Batch: batch size=4, GPUs=8, Gradient Accumulations=5. Total batch size=160
- Learning rate: warmup to 1e-5 for 5,000 steps and then kept constant, AdamW optimiser
Results #
The very first results I saw during after letting run for a decent amount of time looked like this:

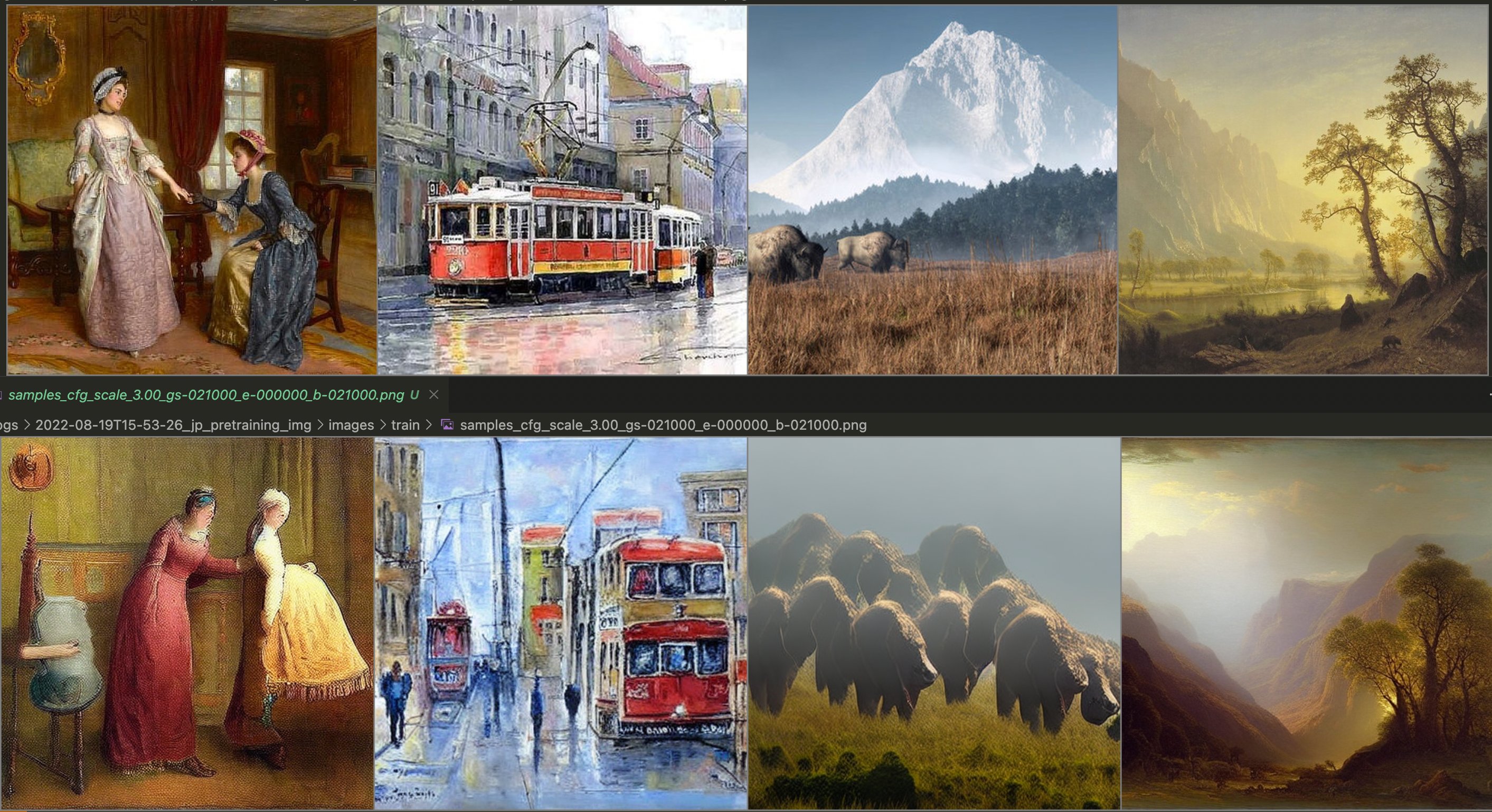
The first batch of results I shared on Twitter showed the classic image variations for some famous images (see if you can guess which ones):




Version 2 #

After retraining the model a little more carefully 3. For v2 I fine tuned only the cross attention weights initially to try and help the model to better adapt to the new conditioning without degrading its performance, then followed that up with a full fine tune at a large batch size. Maybe if I were doing it now I might trying using LoRA. , for longer, and with a bigger batch size, I released a V2 model which gave substantially better results.
Here are some side by side examples of the improved quality of the v2 model, showing the improved fidelity and coherence of the v2 images.


 .
.
Quirks (a.k.a the problem is always image resizing) #
One thing that really baffled me for a long time, was that in the huggingface diffusers port I would get much worse quality images which were always slightly blurred. After scouring the code for what might be the problem it turned out to be the same problem it always is in image processing code, the resizing method. Seriously, if you have an image processing issue, check your image resizing first!
Turns out I accidentally trained the model with antialias=False during resize. So when the huggingface diffusers pipeline applied the "proper" behaviour, i.e. using anti-aliasing, the results were terrible, seems like the model is very sensitive to the resize method used.


 .
.
The other thing I noticed is that my nice example at the top of this post (Girl with a Pearl Earing by Vermeer) didn't produce pleasant variations as before, but now was badly overfit. It's actually a sign of how badly undertrained the first model was, as that particular image occurs many many times in the training data (see these search results).
{kind=link}

Follow ups #
Hopefully the model has been somewhat useful for people, it also showed how adaptable Stable Diffusion is to changing the conditioning, something I've done a bunch of further experiments on. Some of these I've already blogged about: doing CLIP latent space editing and various other experiments.
It was a very popular Huggingface Space, and if you want to try the model yourself, it's probably the easiest way.
It also made an appearance in the paper Versatile Diffusion: Text, Images and Variations All in One Diffusion Model (arxiv). Unfortunately they had done the work before I'd released the v2 model.

And the concept was also the basis for my Image Mixer model (which I'll write up in more detail in future).
It's also possible to use this model as a full on text to image generator by using an existing CLIP text embedding to image embedding prior. I did a little experiment with the LAION prior to show this was possible, but since then the Karlo v1.0 and Kandinsky priors have come out which are probably much better.
Finally if you want to watch a whole talk my me on this and related topics, I gave one at the Hugging Face Diffusers event:
- Previous: The Other Web
- Next: Searching for Generative Train Journeys