Würstchen v2 Pokémon

The second half of 2023 saw a ton of image generation models come out (including our own Midjourney v6 😊), some open source some not and most interesting in their own way.
One particularly neat little model was Würstchen v2. Würstchen v2 makes the interesting choice of learning a Latent Diffusion Model which is conditional not on text embeddings like Stable Diffusion but on spatial image features extracted by and EfficientNet model, this acts like a very compressed latent representation of the original image. Finally a second diffusion model is trained to generate these spatial image features conditional on text embeddings. Essentially this is training a Stable Diffusion like text to image model but using a super compressed (42x) latent space rather than the typical 8x compression for Latent Diffusion models.
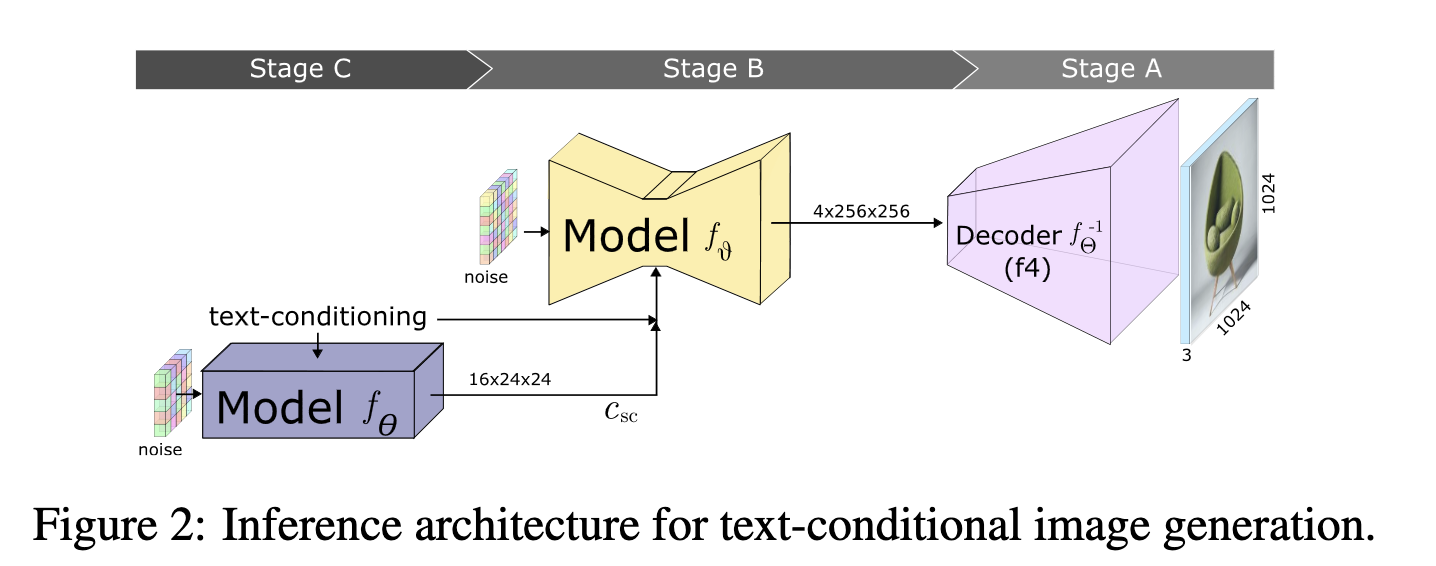
The full pipeline ends up being 3 models: Stage C, a text to very compressed latent image diffusion model; Stage B, a very compressed to less compressed latent image diffusion model; Stage A, the typical latent decoder. With the advantage that Stage B and C can remain fixed for fine tuning, and only Stage C needs to be trained, and given the small spatial dimensions it operates on it can be done so quite efficiently.
To try it out I tested fine tuning with my dataset of cpationed 1. My original dataset was captioned using BLIP, which is a quite out of date captioning model by today's standards. If you're after more detailed captions Sayak Paul kindly shared a version captioned with GPT4 Pokemon images (the same one I used to make text-to-pokemon). After a few tweaks to the training script which didn't seem to be set up for thev v2 model at the time (I originally did this around September 2023) 2. Since then it looks like there is a training script for the Diffusers version of the model. I haven't used it myself but it's probably an easier place to get started yourself. The example even uses the same dataset but I didn't find any example outputs. , I could run a quick fine-tune and start making Pokemon out of text again. After about 5000 training steps the model behaved in a pretty similar way to my original Stable Diffusion version. You can put in names unrelated to Pokemon and get a "Pokemon-ified" version out.
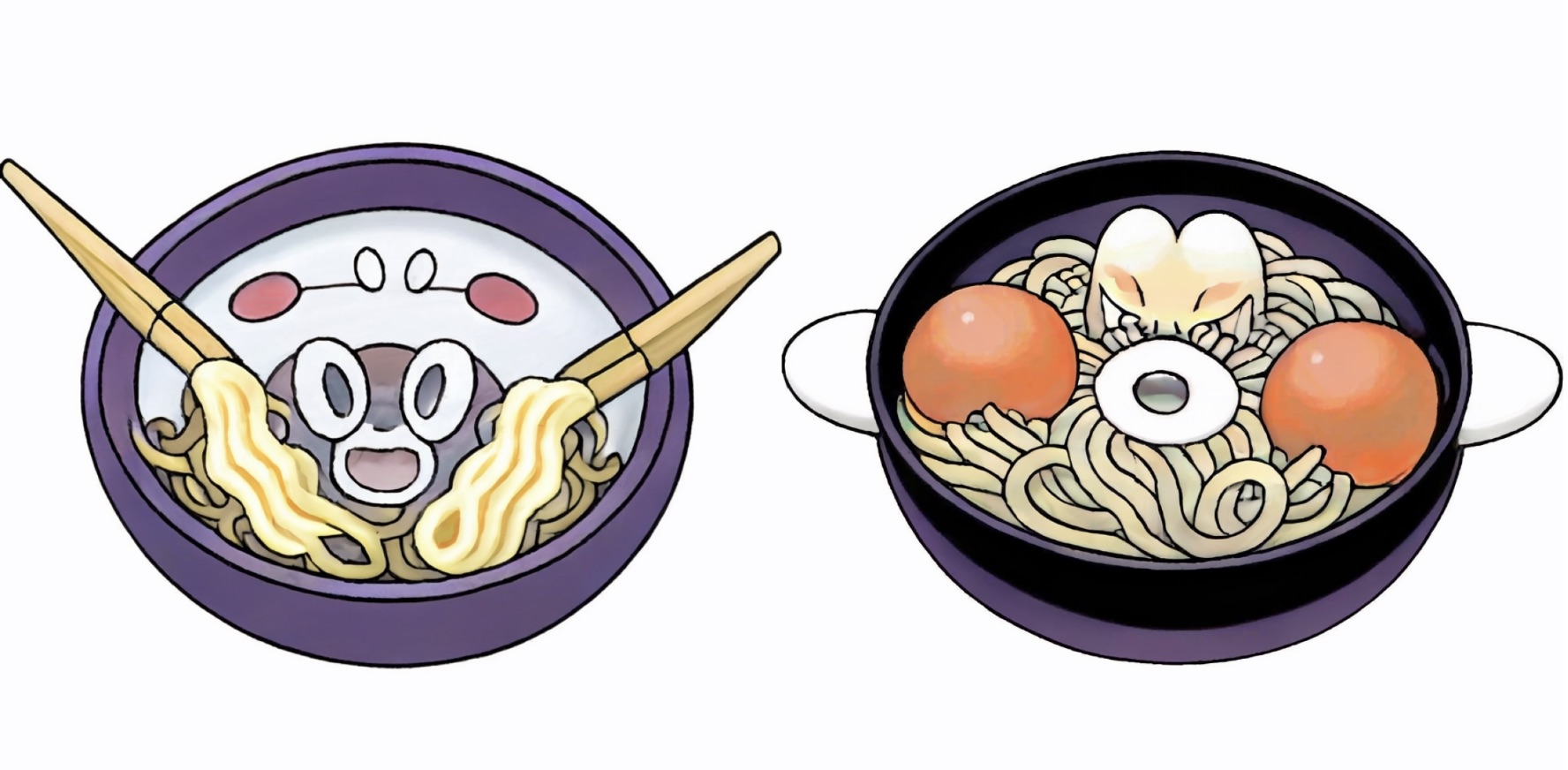
Here are some more example outputs of "Mario", "Girl with a Pearl Earring", "Boris Johnson", and "Ramen". You can compare some of these to the example outputs in my previous Stable Diffusion based model which overall worked marginally better I think.



- Previous: Side notes and a Gallery
- Next: Face Mixer Diffusion